Rappit Undoc: Automate Document Processing
Rappit Undoc is an (Gen)AI-powered adaptable solution for intelligent document processing. Boost your team’s productivity by automatically extracting & processing data from complex and unstructured documents into back-end systems with a solution customized to fit your unique needs.
Your new
way of working
Unlock efficiency with Rappit Undoc
Automatically extract and process data from complex documents with intelligent document processing.
Boost your employee productivity
Enable your employees to spend time on value added activities by eliminating manual data entry and automating repetitive tasks.
Increase throughput time
Drastically reduce turnaround times by processing documents in seconds, instead of minutes or even days.
Reduce cost
Save on the cost of manual work and human mistakes, or an inaccurate OCR solution with high license costs.
Why Rappit Undoc?
A solution adapted to your unique needs.
Easily customizable
Building blocks allow for fast implementation of a customized solution at enterprise scale.
End-to-end solution
An end-user friendly solution with various modules from document capturing to a verification app.
Accurate
Particularly for complex, unstructured documents and less straightforward use-cases. Enabled by training of ML models with your data.
Integrated
Truly automated solution, integrating extracted data in workflows & back-end systems for seamless document processing.
Any document type
Equipped to process any document types in different formats, such as MS Word, PDF, text and pictures, in any language.
Adaptable solution modules
Document ingestion
Scan mailbox for incoming documents or fetch these from cloud storage. Sends documents for conversion and stores/routes them to required destinations.
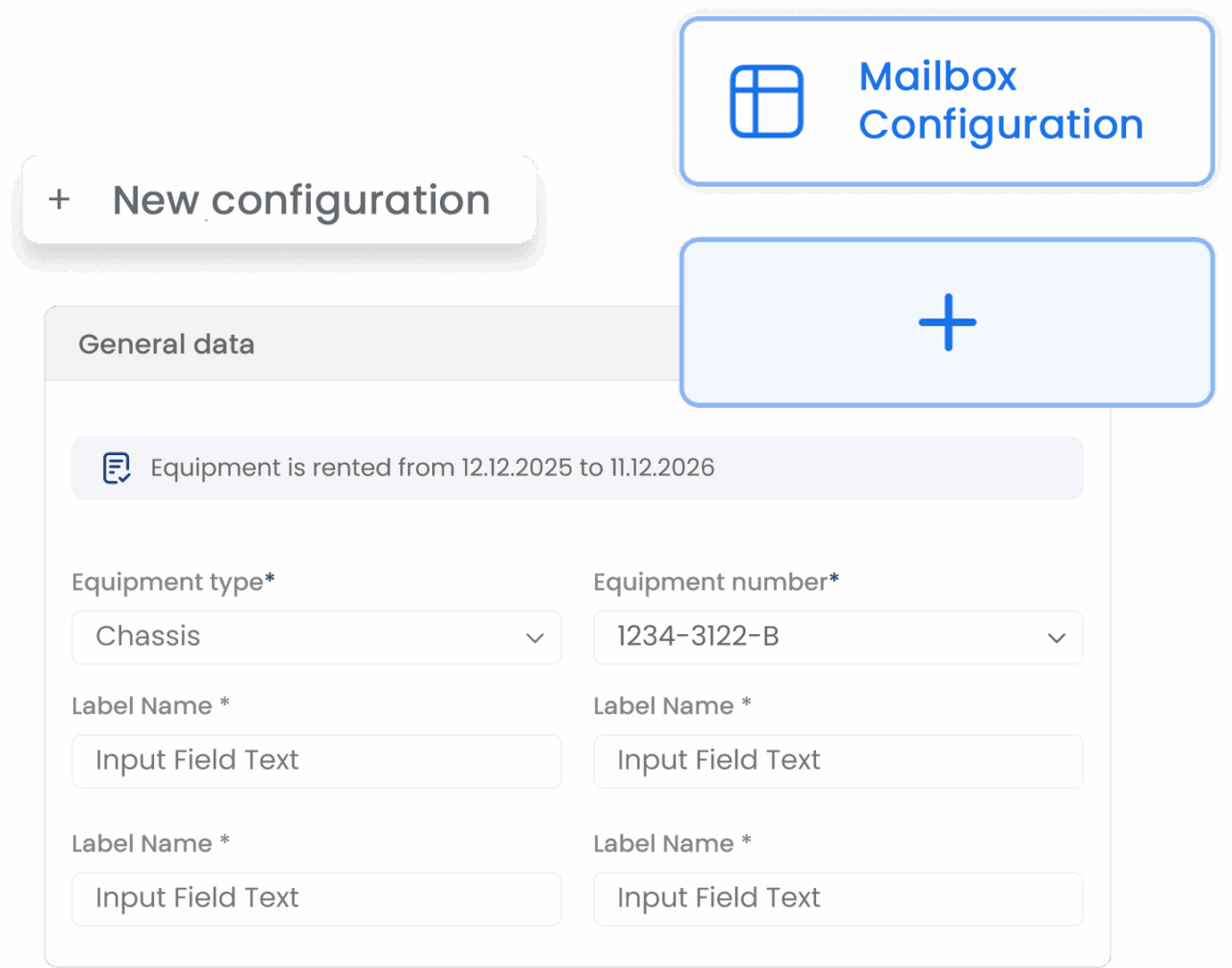
Document conversion & classification
Use OCR and DocAI to extract data from documents and images. Document data extraction based on custom AI/ML models for content classification and entity recognition. With models trained on your data to achieve >95% accuracy.
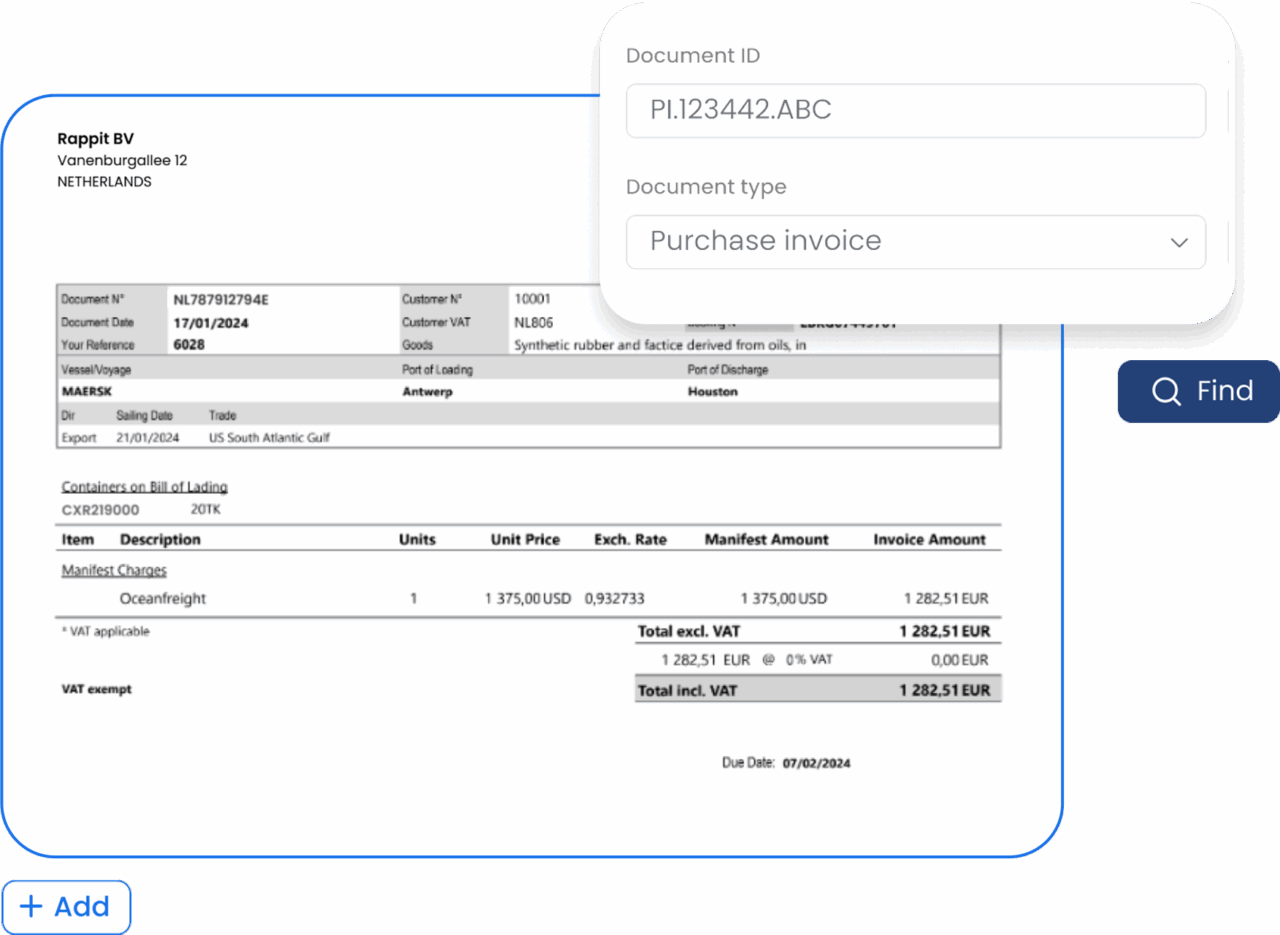
Human-in-the-loop automation
Achieve almost 100% accuracy with a verification app to review output and provide corrections. With a feedback loop to ML models for continuous learning.

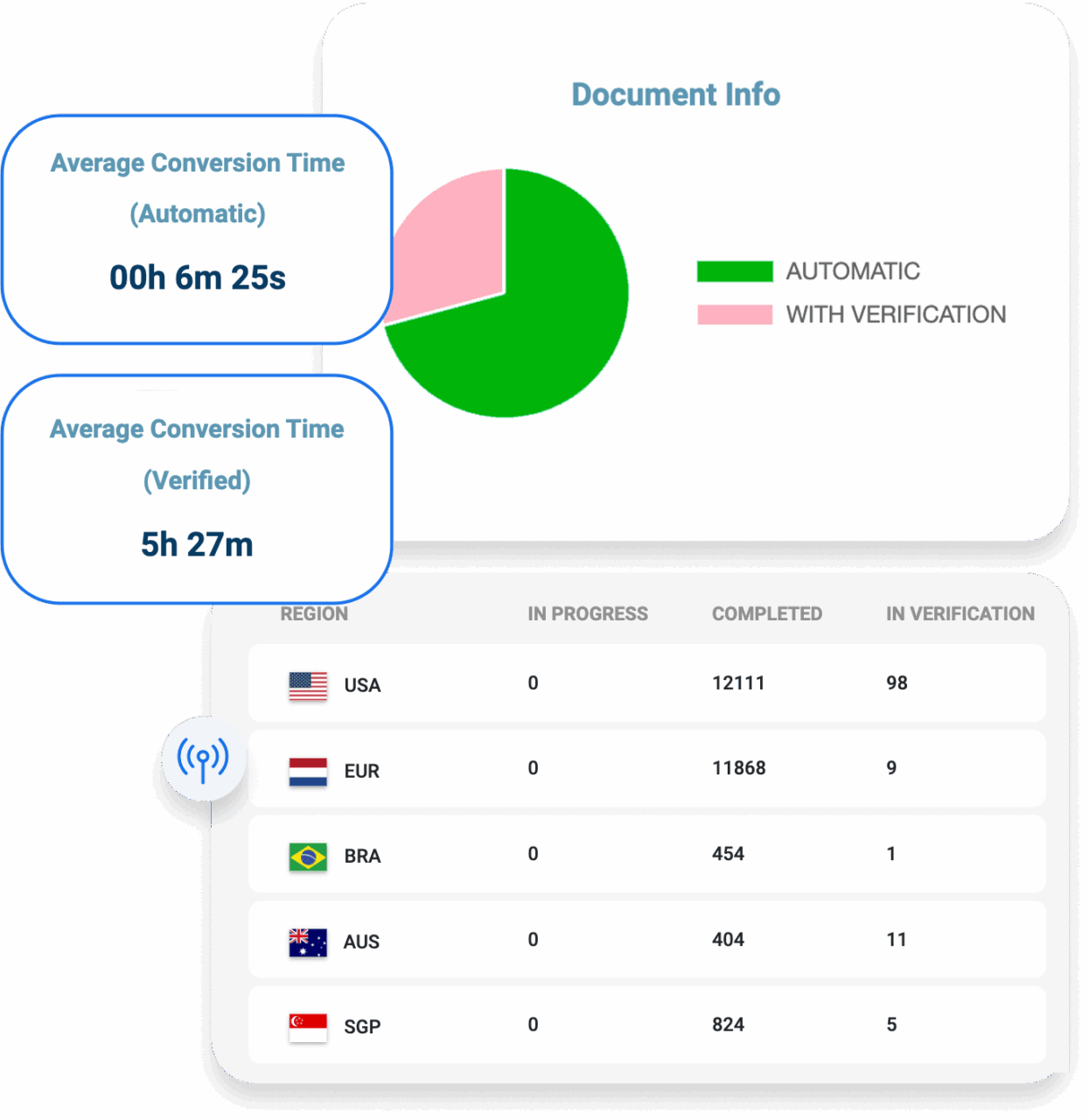
Dashboard for logging, monitoring & reporting
Know the number of documents uploaded or pending for review. Dashboard metrics provide insight into document processing performance, including reports and alerts.
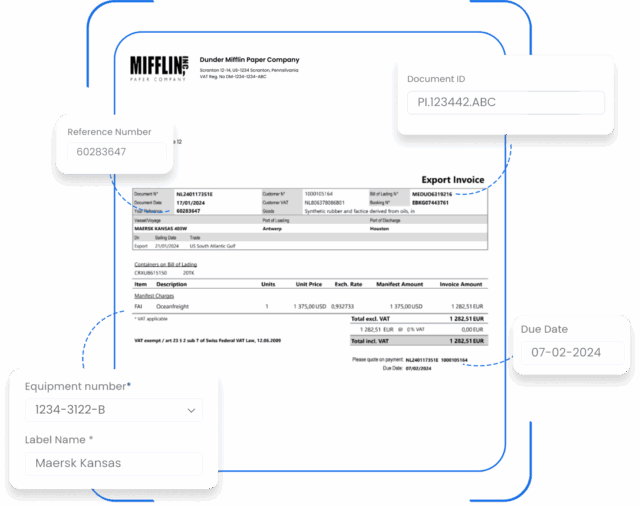
Document management system
Organize document storage, search and retrieval. Easily configure access privileges, lifecycle policies and back-up.

Want to have an in-depth view?
Rappit Undoc boosts productivity by providing a custom intelligent document processing solution for your unique needs.
Follow us on LinkedIn!
Join 11,000+ IT professionals, business leaders, and tech enthusiasts, and receive exclusive updates on how Rappit Undoc is transforming business worldwide.

Powered by Google (gen)Artificial Intelligence
Rappit Undoc incorporates Google’s industry-leading (Generative) Artificial Intelligence & Machine Learning technologies to provide a future-ready solution:
- Gemini for analyzing unstructured data to extract entities, generate useful insights and provide reports in predefined formats.
- Vertex AI for training and serving custom machine learning models.
- DocAI for digitization, document splitting and classification.
Your data, decoded. See the prototype.
Don’t settle for a generic walkthrough. Upload up to 5 documents you find most challenging to process and enter your details. We will schedule a personalised demo based on your data and requirements.
FAQ
What is the difference between OCR and an intelligent document processing solution?
Optical character recognition (OCR) is just one component of an intelligent document processing solution. OCR is a technology that enables you to convert virtually any type of image containing written text (i.e. typed, handwritten or printed) into machine-readable text data. An intelligent document processing solution involves a more advanced process that not only extracts data but also classifies, validates, and integrates it into back-end systems for use in business processes. OCR alone cannot provide the same level of accuracy and efficiency as the combination of technologies used in an intelligent document processing solution. Additionally, an intelligent document processing solution offers scalability and automation, making it more suitable for handling large volumes of (complex) documents or less straightforward use-cases.
What are your target scenarios?
- Standard and non-standard document types requiring high level of machine intelligence in understanding and extracting detailed information (less straightforward use cases not handled well by OCR solutions).
- Building additional business logic with data extracted from documents (e.g. matching invoice lines to receipts for automatic payment approval).
- Companies that are looking to acquire competitive advantage.
- High volumes (that warrant the investment in a dedicated solution).
- Integrating documents in workflows & back-end systems.
How accurate is Rappit Undoc?
Accuracy rates of over 95% are typically achieved. This is due to the use of multiple advanced technologies, such as OCR, (generative) AI and Machine Learning algorithms, which are combined extract and validate data from documents. Additionally, human-in-the-loop validation with the verification app can further improve the accuracy by allowing for feedback and corrections from human input. Rappit Undoc offers a highly accurate solution for managing large volumes of documents with complex data.
Which document types are supported?
Rappit Undoc supports many different types of documents (in different file formats) like purchase invoices, export documents, and test certificates. For each document type customization and training / tuning of models based on your data might be required to achieve highly accurate document processing.
Which languages are supported?
We currently provide support for documents in all languages supported by Google Cloud Vision API. This includes all Latin languages and multiple Asian languages.
Can Rappit Undoc handle handwritten texts?
Yes, it can handle handwritten text (in multiple languages) by employing OCR technology to decipher hard-to-read texts.
What is the impact of Generative AI?
Integrating Google Cloud’s GenAI technology in Rappit Undoc has improved its document processing capabilities, enabling better understanding and interpretation. This has led to more accurate text extraction, improved pattern recognition, and better adaptation to changing formats and languages.
How much does it cost?
The cost depends on the amount of fields and the document volume to be processed, required accuracy and customizations & integrations needed. Get in touch with our experts to receive a custom quote.